はじめに
Oracle Database 11gR2 から、特殊パターン一致文字の % と _ の扱いが変わりました。
Oracle Database 11gR1 までは、いわゆる全角の % と _ が特殊パターン一致文字として有効でしたが、Oracle Database 11g Release 2 からは、これらの全角文字は特殊パターン一致文字ではなく、通常の文字として扱われるようになりました。
11gR1 は 2007年8月 リリース、11gR2 は 2009年9月 リリースで、既にとうの昔に EOL を迎えているため今更ではありますが、古いシステムで対応できていないものもあろうかと思い、念のため残しておこうかと。
Oracle Database における Like 検索
abc% で始まる対象を検索する場合には、以下のように escape 文字を指定する必要があります。
select * from xxx where name like 'abc\%%' escape '\';
Oracle では、デフォルトのエスケープ文字は規定されていないため、escape で指定する必要があります。
つまり、\ をエスケープ文字とすれば、検索条件は以下のように置き換えする必要があります。
%->\%_->\_\->\\
そして古い Oracle では、以下のエスケープも必要でした。
%->\%_->\_
Java を例にすれば、以下のように置換することになるでしょう。
String str = "abc%"; String escaped = str.replaceAll("([%_\\\\%_])", "\\\\$1"); // -> abc\%
abc% は abc\% と置換され、Oracle Database 11gR2 以降では ORA-01424: missing or illegal character following the escape character となります。
ですので、以下のように変更する必要があります。
String escaped = str.replaceAll("([%_\\\\])", "\\\\$1");
全角 % _ が特殊パターン一致文字から除外されたのは
公式な ChangeLog は見つかりませんでした(11.2.0.3 で変更されたという情報はありましたが、詳細は不明です)。
唯一見つけられたのは、Oracle のドキュメント、Like Condition の Note の記載だけでした。
こちらが Oracle Database 11gR1
こちらが Oracle Database 11gR2
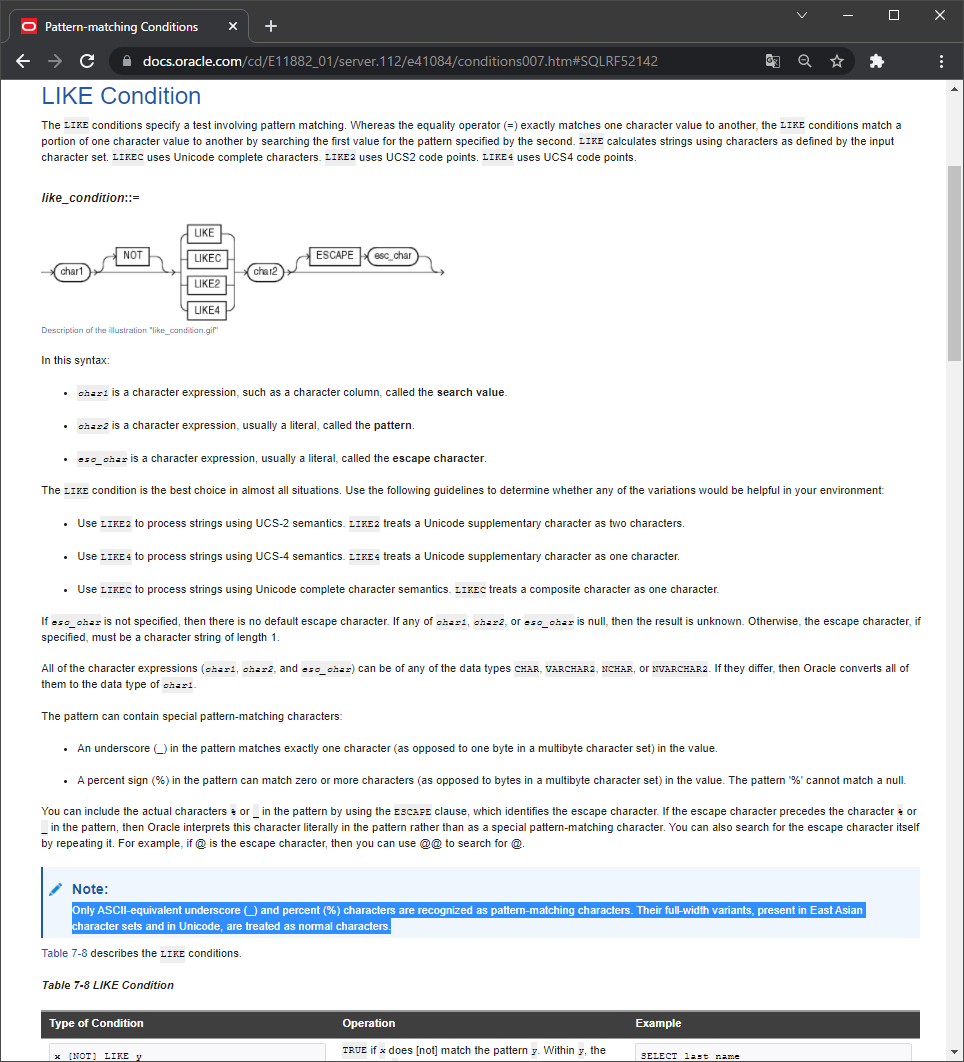
以下の Note が追加されています。
Only ASCII-equivalent underscore (_) and percent (%) characters are recognized as pattern-matching characters. Their full-width variants, present in East Asian character sets and in Unicode, are treated as normal characters.
ASCII表記のアンダースコア(_)およびパーセント(%)文字のみが、パターン一致文字として認識されます。東アジア・キャラクタ・セットおよびUnicodeで表示される全角文字は、通常の文字として扱われます。
各データベースのLike検索エスケープ事情
各データベースの事情は以下のようになります。
| データベース | デフォルトエスケープ文字 | エスケープ対象 | 備考 |
|---|---|---|---|
| Oracle | なし | % _ |
指定したエスケープ文字のエスケープも必要 |
| MySQL | \ |
% _ \ |
デフォルトエスケープ文字を変更時はその文字のエスケープが必要 |
| PostgreSQL | \ |
% _ \ |
デフォルトエスケープ文字を変更時はその文字のエスケープが必要 |
| SQL Server | [] |
% _ [ |
[%] のようにしてエスケープ。ESCAPE 句で任意文字も指定可能 |
| DB2 | なし | % _ % _ |
指定したエスケープ文字のエスケープも必要 |
やはり、MySQL と PostgreSQL が素直で良い感じです。


